Когда понадобится: для оценки взаимоотношений в коллективе, заинтересованности сотрудников в получении результатов и их мотивации.
Тест Вудкока
Инструкция
Прочитайте утверждения, которые описывают Вашу команду, и обведите кружком порядковые номера тех, с которыми Вы согласны. Если Вы считаете, что утверждение не вполне соответствует истине, то оставьте поле для ответа пустым.
Не тратьте много времени, обдумывая каждое утверждение: достаточно нескольких секунд.
Помните, что результаты будут иметь смысл, только если Вы искренни.
Тестовое задание
1. Наша команда испытывает достаток в лидерстве.
2. Кажется, что решения являются принудительными по отношению к нам.
3. Людей не поощряют высказываться откровенно.
4. В трудной ситуации каждый берется за свои интересы.
5. Общение нуждается в улучшении.
6. Решения принимаются на неадекватном уровне иерархии.
7. Некоторые менеджеры неискренни сами с собой.
8. Мы редко подвергаем сомнению основное содержание или пользу наших совещаний.
9. Созданы недостаточные возможности для развития.
10. Мы часто ссоримся с другими подразделениями.
11. Члены команды не общаются друг с другом в достаточной мере.
12. Ясно, что организация ожидает от нашей команды.
13. Принятый порядок редко подвергается сомнению.
14. В действительности никому не ясно, куда мы движемся.
15. Люди не говорят, что они в действительности думают.
16. Люди имеют позицию «моя хата с краю».
17. В команде конфликт носит деструктивный характер.
18. Решения основываются на неадекватной информации.
19. Некоторым менеджерам не доверяют.
20. Мы не учимся на своих ошибках.
21. Менеджеры не помогают своим подчиненным учиться.
22. Отношения с другими группами являются прохладными.
23. Мы не обдумываем хорошо наше положение внутри организации.
24. Наша команда «политически» восприимчива.
25. Мы часто обнаруживаем, что нам недостает нужной квалификации.
26. Мы все очень заняты, но, кажется, везде не успеваем.
27. Спорные вопросы прячутся под ковер.
28. Помогло бы, если бы люди имели больше желания признавать свои ошибки.
29. Имеют место недоверие и враждебность.
30. Люди не допускаются к решениям.
31. Мало лояльности к команде.
32. Мнения извне не приветствуются.
33. Следовало бы иметь большую ротацию работ.
34. Мы редко работаем эффективно вместе с другими командами.
35. Нам не удалось обеспечить сотрудничество с другими командами и подразделениями.
36. Способность работать в команде является критерием отбора при поступлении в эту организацию.
37. Никто не налаживает необходимых связей с другими группами.
38. Мы не тратим требуемого времени на планирование будущего.
39. Деликатных вопросов избегают.
40. Бывает, что кому-то «всадили нож в спину».
41. В действительности мы не работаем вместе.
42. Неподходящие люди принимают решения.
43. Менеджеры являются слабыми и не готовы бороться и требовать внимания к своей точке зрения.
44. Я не получаю достаточной обратной связи.
45. Развиваются несоответствующие виды умений.
46. Помощь не придет из других частей организации.
47. Существует сильное непонимание между нашей командой и профсоюзами, которые оказывают давление на нас.
48. В этой организации вознаграждается слаженность работы в команде.
49. Мы не уделяем достаточно внимания взаимоотношениям.
50. Мы не имеем ясного представления о том, чего от нас ожидают.
51. Честность не является характерной чертой нашей команды.
52. Я не чувствую поддержки со стороны моих коллег.
53. Квалификация и информация распределены недостаточно хорошо.
54. Имеются сильные личности, которые идут своим собственным путем.
55. Чувство собственного достоинства не одобряется.
56. Нам следует уделять больше времени обсуждению методов работы.
57. Менеджеры не принимают всерьез личное развитие.
58. Другие части организации нас не понимают.
59. Нам не удается донести наше сообщение к внешнему миру.
60. Люди в команде имеют хорошие связи с другими членами организации.
61. Часто мы достигаем решений слишком быстро.
62. Образ действий, при котором ценится личность, имеет мало общего с тем, что достигнуто.
63. Слишком много секретов.
64. Конфликтов избегают.
65. Разногласия разлагают.
66. Приверженность к решениям низка.
67. Наши менеджеры полагают, что более строгий надзор улучшает результат.
68. Слишком много запретов в нашей команде.
69. Очевидно, что в другом подразделении имеются лучшие возможности.
70. Мы тратим много энергии на защиту наших границ.
71. Члены команды не понимают, чего от них ожидают.
72. Культура организации поощряет слаженную работу в команде.
73. Мы не уделяем достаточно внимания новым идеям.
74. Приоритеты не ясны.
75. Люди не вовлекаются в достаточной мере в принятие решений.
76. Слишком много взаимных обвинений и упреков.
77. Не всегда выслушивают.
78. Мы не используем в полном объеме навыки, которыми обладаем.
79. Менеджеры полагают, что люди по своему существу ленивы.
80. Мы тратим много времени на то, чтобы делать, и не уделяем достаточно времени тому, чтобы думать.
81. Не поощряется стремление личности к росту.
82. Мы не стараемся понять точку зрения других команд.
83. Нам не удается выслушать наших клиентов.
84. Команда работает в соответствии с целями организации.
Спасибо за ответы!
Ключ к тесту Вудкока для оценки эффективности команды
Описание
Тест Вудкока разработан для оценки эффективности работы в команде. Позволяет оценить взаимоотношения в коллективе, заинтересованность сотрудников в получении результатов и их мотивацию. Также учитываются лояльность компании и уровень взаимодействия между подразделениями организации.
Принцип тестирования несложен. Каждый член команды независимо от должности заполняет вопросник, в который входят 84 утверждения. Затем по специальной таблице выполняются подсчет результатов и их анализ.
Если вы сомневаетесь, что члены команды будут честно отвечать на вопросы, постарайтесь обеспечить анонимность тестирования. По большому счету это уже показатель взаимоотношений в команде. Тем не менее провести тестирование все равно полезно, так как его результаты позволяют точнее выявить недостатки в работе команды.
Кроме того, очень полезно сравнить результаты тестов руководителей и их подчиненных. Это позволяет оценить атмосферу в команде и определить степень доверия подчиненных к руководству.
Ключ к тесту
Перенесите выделенные ответы из анкеты в таблицу результата. Посчитайте количество отметок в каждом столбце. Запишите количество в строке «Итого».
Таблица результата
| А | В | С | D | Е | F | G | Н | I | J | К | L | |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | |
| 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | |
| 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 | |
| 61 | 62 | 63 | 64 | 65 | 66 | 67 | 68 | 69 | 70 | 71 | 72 | |
| 73 | 74 | 75 | 76 | 77 | 78 | 79 | 70 | 81 | 82 | 83 | 84 | |
| Итого |
Перенесите счет столбцов из строки «Итого» в таблицу.
Перевод : Ольга Алифанова
В обеспечении качества различают верификацию и валидацию. Верификация отвечает на вопрос, правильно ли мы создаем продукт, а валидация – на вопрос, а то ли мы вообще создаем, что нужно. Некоторые люди проводят водораздел между обеспечением качества и тестированием, исходя именно из этих определений.
С моей точки зрения, использование терминов "верификация" и "валидация" может привести к ложным дихотомиям. Для меня тестирование – это деятельность, связанная с дизайном , и поэтому покрывает довольно широкую область. Я верю, что тесты могут стать неким "общим языком ". Я верю, что тесты могут напрямую кодировать спецификации и требования. И я верю, что тесты – это источник знаний об области или продукте. Слишком большой упор на разницу между верификацией и валидацией – это неэффективный и не результативный способ понять, как именно тестирование дополняет обеспечение качества.
С моей точки зрения, неспособность воспринимать тестирование и обеспечение качества, как два различных, дополняющих друг друга процесса – это восприятие, которому явно не хватает некоторого изящества.
На самом деле я согласен, что различия между верификацией и валидацией вполне оправданы. В конце концов, эффективность – это способность делать что-то правильно. Результативность, с другой стороны – это способность выдавать правильный результат. Эффективность сфокусирована на процессе и нацелена на доведение его до конца, а результативность – на продукте (то есть, собственно, на результате этого процесса). Можно сказать и так: эффективность концентрируется в первую очередь на том, чтобы избежать ошибок, а результативность – на успехе вне зависимости от количества промахов, допущенных по пути.
Однако мне кажется, что есть способ различать эффективность и результативность, который куда лучше понимания разницы между верификацией и валидацией. Ведь тестирование прямо-таки требует гибкости и инноваций.
И это именно та точка, в которой возникает любопытный парадокс. Для постоянного, непрерывного поддержания эффективности вам требуется приличный уровень дисциплины и твердости. Однако именно дисциплина и устойчивость к переменам лишают процессы гибкости! Если вы делаете одно и то же одинаково раз за разом, вас никогда не осенит ничем инновационным.
Так как эффективность в данном контексте связана с верификацией, это означает, что верификация может превратиться в статическую деятельность.
Результативность, напротив, куда лучше адаптируется к переменам и требует большой гибкости. Для достижения хороших результатов нужно поощрять инновацию, потому что тогда люди будут задумываться о том, что именно они сейчас делают, и стоит ли заниматься именно этим в конкретном контексте и при воздействии конкретных факторов. Однако эта гибкость и адаптивность ведут к чересчур большому богатству выборов и потенциальной неспособности на сознательные рутинные усилия, которые можно будет воспроизвести и вне текущей ситуации.
Так как эффективность в нашем контексте увязана с валидацией, все вышесказанное означает, что валидация может стать чересчур динамичным видом деятельности.
И тут-то в игру должно вступать изящество решений, разрывающее этот порочный круг и дающее вам возможность оценить свою эффективность и результативность, смотря на нее другими глазами. Изящество решений не просто отвечает на вопросы, сделали ли мы что-то лучше, или подумали ли мы о чем-то получше, а скорее дает ответ, стали ли мы лучше понимать, что происходит, создали ли мы базу для будущей деятельности?
Изящество можно рассматривать в том числе как минимизацию сложности. В мире разработки люди часто делят сложность решений на обязательную и случайную. Следовательно, для того, чтобы решения в тестировании были изящными, они должны состоять только из "обязательной сложности" и практически не содержать случайной. Звучит, наверное, загадочно? Да, возможно, так как сколько людей – столько мнений о том, где начинается "сложность". Для меня сложность решений в тестировании возникает, когда в системе нет выборов и в наличии высокая неопределенность.
Если вы позволяете тестированию быть инновационным и гибким (то есть результативным), но при этом поддерживаете определенный уровень жесткости и дисциплины (эффективность), у вас должен быть некий свод правил насчет того, как управляться с выбором (в смысле, как предоставлять этот выбор) и неопределенностью (как ее уничтожать).
Не буду занудничать на эту тему, а просто приведу примеры того, о чем я говорю. В своих примерах я хочу попробовать заставить команды тестирования думать о своих тестах, используя термины "эффективность", "результативность" и "изящество". Начну с некоторых аксиом (не подберу другого слова) и постараюсь сделать свои примеры как можно короче и понятнее. Есть вещи, в которые должна верить вся команда – или, как минимум, действовать так, как будто она в них верит. И первая же моя аксиома утверждает то, о чем я выше говорил!
- Тестирование может выполняться эффективно, результативно и изящно.
- Тестирование требует активных, профессиональных, технических исследований.
- Цель тестирования – это внятное донесение нужной информации вовремя.
- Тестировщики в каком-то смысле – писатели и редакторы. Следовательно, этика изящества и профессиональная гордость – непременные атрибуты хорошей, мотивированной работы с должным уровнем внимания.
Вот несколько примеров, иллюстрирующих эти положения. Для начала давайте рассмотрим все эти концепции применительно к тесту.
- Эффективный тест должен концентрироваться на вводе, процессе, выводе.
- Результативный тест должен быть выразительным и демонстрировать цель теста.
- Эффективный тест должен фокусироваться на одном внятном результате конкретного действия, а не на нескольких одновременно.
- Результативный тест группирует связанные между собой наблюдения.
- Эффективный тест дает конкретный пример нужных данных.
- Результативный тест рассказывает про общие условия, под которые должны попадать тестируемые данные.
- Изящный тест описывает конкретное поведение системы и ее функциональность.
Теперь давайте применим эти концепции к тест-сьюту:
- Эффективный тест-сьют определяет, какие данные будут валидными, а какие нет.
- Эффективный тест-сьют проверяет и валидные, и невалидные данные.
- Результативный тест-сьют группирует типы данных в классы.
- Изящный тест-сьют может составляться для исследований задач бизнеса и его процессов.
И, наконец, давайте приложим эти определения к тестированию как виду деятельности:
- Эффективное тестирование использует скрипты, структурирующие исследовательский процесс.
- Результативное тестирование применяет исследовательские практики, которые привносят в скрипты вариативность.
- Изящное тестирование использует скриптованные исследовательские практики, чтобы продемонстрировать ценность приложения для потребителя путем изучения того, как оно используется.
- Эффективное тестирование использует сценарии, показывающие, как продукт реализует свое назначение.
- Результативное тестирование использует сценарии, которые демонстрируют, что должно произойти, чтобы пользовательская потребность была удовлетворена.
- Изящное тестирование описывает требования и демонстрирует возможности приложения.
Все это важно осознавать, так как то, что вы делаете и то, как именно вы это делаете – это основа того, что и как вы будете делать в будущем. Это также поддерживает групповую динамику и размышления о вышеприведенных концепциях. Вот что я имею в виду:
- Некоторые тестировщики предпочитают называть тест-кейсы "условиями теста". Некоторые – наоборот. Кто-то игнорирует оба термина. Я считаю, что результативное тестирование группирует тестовые условия и делает их вариациями тест-кейсов. Результативное тестирование использует условия теста, заданные особыми параметрами нужных данных.
- Терминология "позитивное/негативное тестирование" давно уже вышла из моды у опытных тестировщиков. Изящное тестирование концентрируется на описании валидных и невалидных условий. Это означает, что тестировщики должны эффективно и результативно тестировать, определяя все условия теста, которые могут изменяться (что приводит, в свою очередь, к группировке валидных и невалидных условий), а также убедиться, что они принимают взвешенные решения, выбирая определенные наборы данных и игнорируя остальные.
- Изящные тесты – это чемпионы ваших тестов. Если у вас есть группа тестов, проверяющих по факту схожие вещи, а ваше время ограничено – вы успеете прогнать только часть из них. В таких случаях используйте тесты, которые с большой долей вероятности вскроют целый пласт ошибок. Такие тесты могут быть крайне изящными.
- Эффективный тест должен быть ни слишком простым, ни чересчур сложным. Конечно, возможно впихнуть в один кейс целую серию проверок, но возможные побочные эффекты такого способа создания тестов могут замаскировать кучу багов. Следовательно, результативные кейсы должны включать разные точки наблюдения (или другой путь к той же самой точке наблюдения), и выполняться по отдельности.
- Некоторые техники тестирования крайне эффективны в плане выбора специфических данных и организации этих данных в комбинации или последовательности. Но изящное решение возникнет, когда тестировщики выбирают эти данные, исходя из взаимодействия разных функциональностей и потоков данных, и исследуют пути через пользовательский интерфейс с пониманием того, как живой человек будет использовать эту систему.
- Результативный кейс должен быть способен дать вам информацию. Вам нужны тесты, которые дадут ответы на вопросы, заданные вами. Цель теста – совершенно необязательно поиск бага, его цель – это сбор информации. Тест ценен не тогда, когда он может найти баг – он должен быть способен снабжать вас информацией (хотя эта информация может заключаться и в наличии бага, если с приложением что-то не так). Изящное решение всегда нацелено на получение определенной информации в ходе тестирования.
- Результативное тестирование нуждается в понимании требований и их связи с тем, как пользователи воспринимают ценность нашего продукта. Нам нужно понимать наших пользователей, а не просто читать спецификации и требования! Изящное тестирование использует эвристики для структурирования этого понимания. Оно также заставляет тестирование рассказывать захватывающие истории о действиях реальных людей.
Возможно, мне с самого начала стоило отметить, что у меня не было цели выставить себя истиной в последней инстанции в плане ответа на вопрос, какое тестирование будет эффективным, результативным и изящным. Я только хотел донести свою позицию: я считаю, что команды тестирования, которые понимают разницу между этими концепциями, способны
В. В. Одинцова
Пользуясь многочисленными психодиагностическими методиками, мы редко задумываемся о качестве этих рабочих инструментов. И напрасно. Ведь любому практикующему психологу известно, что ни одно психологическое обследование невозможно без хорошего диагностического инструментария.
При этом популярные сборники психологических тестов, широко публикуемые в последнее время, к сожалению, не могут удовлетворить требованиям настоящего профессионала, который должен быть уверен в диагностических возможностях того инструмента, который он использует в своей работе. Поэтому, проблема поиска грамотно разработанной и надежной диагностической методики остается актуальной .
Основной задачей HR-Лаборатории Human Technologies является разработка качественной продукции. Одним из условий создания такой продукции являются периодические проверки тестовых методик на предмет их соответствия ряду психометрических требований (валидности, надежности, репрезентативности, достоверности). Для этого, после набора достаточного количества протоколов проводится статистический анализ тестовых методик.
Рассмотрим психометрический анализ (общая выборка которого составила 660 человек).
Данный тест, разработанный в 90-е гг., предназначен для экспресс-диагностики уровня выраженности пяти так называемых "больших" факторов темперамента и характера и используется для исследования личности взрослых людей с целью профотбора, профконсультации, определения направлений психологической помощи, комплектования групп, самопознания и т.п.
Основой универсальности "Большой пятерки факторов" является их кросс-ситуационность: факторы глобальной функционально-деятельностной оценки человека приложимы практически к любой ситуации социального поведения и предметной деятельности, в которых обнаруживаются устойчивые различия между людьми.
Опросник включает 75 пунктов по три варианта ответа в каждом.
ШКАЛЫ теста представляют собой точное воспроизведение факторов "Большой Пятерки" в их международном варианте (за исключением пятого фактора, который в ряде западных версий B5 обозначается как "открытость новому опыту - ограниченный практицизм"):
- экстраверсия - интроверсия
- согласие - независимость
- организованность - импульсивность
- эмоциональная стабильность - тревожность
- обучаемость - инертность
1. Проверка валидности
При проверке существующих шкал традиционным способом - путем расчета корреляций между ответами на вопросы и суммарным баллом по шкале - мы выяснили, что практически все пункты значимо коррелируют со "своими" шкалами со средним коэффициентом корреляции равным 0,35.
При проверке содержательной валидности теста были проанализированы формулировки заданий теста, содержательно отражающие соответствующую предметную область (область поведения) и имеющие значимую (положительную или отрицательную) корреляцию с суммарным баллом:
| Шкала | Пример заданий теста | Коэффициент корреляции |
| ЭКСТРАВЕРСИЯ | Для меня важно высказать свое мнение окружающим | (0,31) |
| Я люблю участвовать во всевозможных конкурсах, соревнованиях и т.п. | (0,41) | |
| Мне нравится ходить в гости и знакомиться с новыми людьми | (0,5) | |
| СОГЛАСИЕ | Большинству людей нельзя доверять | (-0,23) |
| Мои интересы для меня превыше всего | (-0,22) | |
| "Кто людям помогает, тот тратит время зря, хорошими делами прославиться нельзя" | (-0,3) | |
| "Каждый - сам за себя" - вот принцип, который не подведет | (-0,4) | |
| САМОКОНТРОЛЬ | Когда я ложусь спать, то уже наверняка знаю, что буду делать завтра | (0,37) |
| Взяв книгу, я всегда ставлю ее на место | (0,35) | |
| Перед ответственными делами я всегда составляю план их выполнения | (0,37) | |
| СТАБИЛЬНОСТЬ | Я легко краснею | (-0,28) |
| Если я уловил(а) возникновение нежелательной ситуации на работе, то это всегда вызывает у меня тягостное сомнение до тех пор, пока ситуация не прояснится | (-0,3) | |
| В конце дня я обычно устаю настолько, что любая мелочь начинает выводить из себя | (-0,32) | |
| Испортить мне настроение совсем просто | (-0,42) |
Анализ приведенных формулировок говорит о достаточно высокой содержательной валидности теста.
2. Проверка надежности
Надежность теста как средства измерения определяется низкой вероятностью ошибок измерения тестовых баллов и тем, в какой мере результаты измерений воспроизводятся при многократном использовании теста по отношению к данной группе испытуемых. Чтобы оценить вклад различных источников в ошибку измерения, необходимо использовать разные способы оценки надежности. Особый интерес представляет оценка внутренней согласованности теста, она обуславливает ту часть ошибки, которая связана с отбором заданий.
Оценка внутренней согласованности теста производилась посредством расчета альфа-коэффициента Кронбаха. Данный коэффициент представляет собой оценку надежности, базирующуюся на гомогенности шкалы или сумме корреляций между ответами испытуемых на вопросы внутри одной и той же тестовой формы.
В нашем случае рассчитанный для каждой шкалы альфа-коэффициент надежности Кронбаха показал в целом вполне приличный уровень внутренней согласованности, традиционный для личностных экспресс-опросников, в которых субшкалы содержат ограниченное число пунктов (менее 20):
Напомним, что строгим психометрическим требованиям, предъявляемым к эффективно работающему личностному тесту, соответствует значение альфа-коэффициентов выше 0,8.
В нашем же случае относительно низкий уровень значения коэффициентов надежности Кронбаха можно объяснить содержательной объемностью данных шкал: на каждую шкалу приходится по 15 разноплановых вопросов, что позволяет расширить область охвата исследуемых факторов, жертвуя вместе с тем высоким уровнем внутренней согласованности.
Особенно остро это сказалось на факторных шкалах "СОГЛАСИЕ" и "ОБУЧАЕМОСТЬ", по которой альфа-коэффициент оказался ниже 0,6.
3. Проверка репрезентативности
При переходе от выборки стандартизации (рис.1 - 300 человек) к выборке популяции (рис.2 - 660 человек) проявляется устойчивость конфигурации распределения тестовых баллов, что говорит о репрезентативности тестовой методики:
Рис.1. Выборка стандартизации (300 человек)

Рис.2. Выборка популяции (660 человек)
Помимо визуальной схожести этих распределений, использованный нами статистический хи-квадрат критерий Пирсона показал следующую степень сходства распределений:
Данные значения хи-квадрата попадают в промежуток неопределенности: когда нельзя однозначно принять или однозначно отвергнуть гипотезу о согласованности распределений.
Такой результат может быть обусловлен основным свойством экспресс-теста, а именно - малым количеством вопросов, работающих на каждую шкалу. Учитывая этот факт, результаты проверки репрезентативности можно признать удовлетворительными.
4. Проверка достоверности
Так как испытуемые, проходившие тестирование на сайте, находились в ситуации клиента (были заинтересованы в достоверных результатах), то с высокой вероятностью полученные результаты можно считать достоверными.
Однако в ситуации экспертизы (когда в результатах тестирования заинтересовано третье лицо), данные могут искажаться от вмешательства сознательных фальсификаций (лжи, неискренности испытуемого) или бессознательных мотивационных факторов. Чтобы избежать этого в версию, предназначенную для подобных случаев (B5splus), была добавлена шкала лжи (в данный момент эта версия проходит апробацию на нашем сайте) .
Полученные результаты являются свидетельством высокого качества и эффективности методики, что немаловажно, ведь профессиональный уровень специалиста, зачастую, определяется тем инструментом, которым он пользуется.
Однако, следует помнить, что даже мощный современный инструмент не гарантирует полного отсутствия ошибок. Для того чтобы избежать их, мало иметь компьютер и тестовую программу к нему. Обязательно нужен еще и опытный психолог, контролирующий выполнение теста. Так что наличие тестов, прошедших серьезную психометрическую адаптацию, вовсе не отменяет профессионализма и опыта психолога, призванного проверять правдоподобность тестовых результатов с использованием параллельных источников информации (включая собственное наблюдение, беседу и т.п.).
Каждый раз, когда мы заваливаем очередной релиз, начинается суета. Сразу появляются виноватые, и зачастую – это мы, тестировщики. Наверное это судьба – быть последним звеном в жизненном цикле программного обеспечения, поэтому даже если разработчик тратит уйму времени на написание кода, то никто даже не думает о том, что тестирование – это тоже люди, имеющие определенные возможности.
Выше головы не прыгнуть, но можно же работать по 10-12 часов. Я очень часто слышал такие фразы)))
Когда тестирование не соответствует потребностям бизнеса – то возникает вопрос, зачем вообще тестирование, если они не успевают работать в установленные сроки. Никто не думает о том, что было раньше, почему требования нормально не написали, почему не продумали архитектуру, почему код кривой. Но зато когда у вас дедлайн, а вы не успеваете завершить тестирование, то тут вас сразу начинают карать…
Но это было пару слов о нелегкой жизни тестировщика. Теперь к сути 🙂
После пару таких факапов все начинают задумываться, что не так в нашем процессе тестирования. Возможно, вы, как руководитель, вы понимаете проблемы, но как их донести до руководства? Вопрос?
Руководству нужны цифры, статистика. Простые слова – это вас послушали, покивали головой, сказали – “Давай, делай” и все. После этого все ждут от вас чуда, но даже если вы что-то предприняли и у вас не получилось, вы или Ваш руководитель опять получает по шапке.
Любое изменение должно поддерживаться руководством, а чтобы руководство его поддержало, им нужны цифры, измерения, статистика.
Много раз видел, как из таск-трекеров пытались выгружать различную статистику, говоря, что “Мы снимаем метрики из JIRA”. Но давайте разберемся, что такое метрика.
Метрика - технически или процедурно измеримая величина, характеризующая состояние объекта управления.
Вот посмотрим – наша команда находит 50 дефектов при приемочном тестировании. Это много? Или мало? Говорят ли Вам эти 50 дефектов о состоянии объекта управления, в частности, процесса тестирования?
Наверное, нет.
А если бы Вам сказали, что количество дефектов найденных на приемочном тестировании равно 80%, при том, что должно быть всего 60%. Я думаю тут сразу понятно, что дефектов много, соответственно, мягко говоря, код разработчиков полное г….. неудовлетворителен с точки зрения качества.
Кто-то может сказать, что зачем тогда тестирование? Но я скажу, что дефекты – это время тестирования, а время тестирования – это то, что напрямую влияет на наш дедлайн.
Поэтому нужны не просто метрики, нужны KPI.
KPI – метрика, которая служит индикатором состояния объекта управления. Обязательное условие – наличие целевого значения и установленные допустимые отклонения.
То есть всегда, строя систему метрик, у вас должна быть цель и допустимые отклонения.
Например, Вам необходимо (Ваша цель), чтобы 90% всех дефектов решались с первой итерации. При этом, вы понимаете, что это не всегда возможно, но даже если количество дефектов, решенных с первого раза, будет равняться 70% – это тоже хорошо.
То есть, вы поставили себе цель и допустимое отклонение. Теперь, если вы посчитаете дефекты в релизе и получите значение в 86% – то это конечно не хорошо, но и уже не провал.
Математически это будет выглядеть, как:
Почему 2 формулы? Это связано с тем, что существует понятие восходящих и нисходящих метрик, т.е. когда наше целевое значение стремится к 100% или к 0%.
Т.е. если мы говорим, к примеру, о количестве дефектов, найденных после внедрения в промышленной эксплуатации, то тут, чем меньше, тем лучше, а если мы говорим о покрытии функционала тест-кейсами, то тогда все будет наоборот.
При этом не стоит забывать о том, как рассчитывать ту или иную метрику.
Для того, чтобы получить необходимые нам проценты, штуки и т.д., нужно производить расчет каждой метрики.
Для наглядного примера я расскажу Вам о метрике “Своевременность обработки дефектов тестированием”.
Используя аналогичный подход, о котором я рассказал выше, мы также на основе целевых значений и отклонений формируем показать KPI для метрики.
Не пугайтесь, в жизни это не так сложно, как выглядит на картинке!

Что мы имеем?
Ну понятно, что номер релиза, номер инцидента….
Critical - коэф. 5,
Major - коэф. 3,
Minor - коэф. 1,5.
Далее необходимо указать SLA на время обработки дефекта. Для этого определяется целевое значение и максимально допустимое время ретестирования, аналогично тому, как я описывал это выше для расчета показателей метрик.
Для ответа на эти вопросы мы сразу перенесемся к показателю эффективности и сразу зададим вопрос. А как рассчитать показатель, если значение одного запроса может равняться “нулю”. Если один или несколько показателей будет равно нулевому значению, то итоговый показатель при этом будет очень сильно снижаться, поэтому возникает вопрос, как наш расчет сбалансировать так, чтобы нулевые значения, к примеру, запросов с коэффициентом тяжести “1” не сильно влияли на нашу итоговую оценку.
Вес - это значение, которое необходимо нам для того, чтобы сделать наименьшим влияние запросов на итоговую оценку с низким коэффициентом тяжести, и наоборот, запрос с наибольшим коэффициентом тяжести имеет серьезное влияние на оценку, при условии того, что мы просрочили сроки по данному запросу.
Для того, чтобы у вас не сложилось непонимания в расчетах, введем конкретные переменные для расчета:
х - фактические время, потраченное на ретестирование дефекта;
y - максимально допустимое отклонение;
z - коэффициент тяжести.
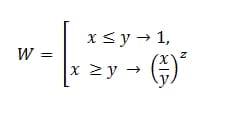
Или на обычно языке, это:
W = E СЛИ (x<=y,1,(x/y)^z)
Таким образом, даже, если мы вышли за установленные нами рамки по SLA, наш запрос в зависимости от тяжести не будет серьезно влиять на наш итоговый показатель.
Все как и описывал выше:
х – фактические время, потраченное на ретестирование дефекта;
y – максимально допустимое отклонение;
z – коэффициент тяжести.
h –
плановое время по SLA
Как это выразить в математической формуле я уже не знаю, поэтому буду писать программным языком с оператором ЕСЛИ.
R = ЕСЛИ(x<=h;1;ЕСЛИ(x<=y;(1/z)/(x/y);0))
В итоге мы получаем, что если мы достигли цели, то наше значение запроса равно 1, если вышли за рамки допустимого отклонения, то рейтинг равен нулевому значению и идет расчет весов.
Если наше значение находится в пределах между целевым и максимально допустимым отклонением, то в зависимости от коэффициента тяжести, наше значение варьируется в диапазоне .
Теперь приведу пару примеров того, как это будет выглядеть в нашей системе метрик.
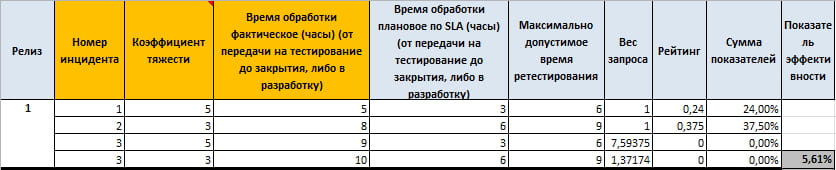
Для каждого запроса в зависимости от их важности (коэффициент тяжести) имеется свой SLA.
Что мы тут видим.
В первом запросе мы на час всего лишь отклонились от нашего целевого значения и уже имеем рейтинг 30%, при этом во втором запросе мы тоже отклонились всего на один час, но сумма показателей уже равна не 30%, а 42,86%. То есть коэффициенты тяжести играют важную роль в формировании итогового показателя запроса.
При этом в третьем запросе мы нарушили максимально допустимое время и рейтинг равен нулевому значению, но вес запроса изменился, что позволяет нам более правильно посчитать влияние этого запроса на итоговый коэффициент.
Ну и чтобы в этом убедиться, можно просто посчитать, что среднее арифметическое показателей будет равно 43,21%, а у нас получилось 33,49%, что говорит о серьезном влиянии запросов с высокой важностью.
Давайте изменим в системе значения на 1 час.
при этом, для 5-го приоритета значение изменилось на 6%, а для третьего на 5,36%.
Опять же важность запроса влияет на его показатель.

Все, мы получаем итоговый показатель метрики.
Что Важно!
Я не говорю о том, что использование системы метрик нужно делать по аналогии с моими значениями, я лишь предлагаю подход к их ведению и сбору.
В одной организации я видел, что был разработан собственный фреймворк для сбора метрик из HP ALM и JIRA. Это действительно круто. Но важно помнить, что подобный процесс ведения метрик требует серьезного соблюдения регламентных процессов.
Ну и что самое важное – только вы можете решить, как и какие метрики Вам собирать. Не нужно копировать те метрики, которые вы собрать не сможете.
Подход сложный, но действенный.
Попробуйте и возможно у вас тоже получится!
Александр Мешков – Chief Operations Officer в Перфоманс Лаб, – обладает опытом более 5 лет в области тестирования ПО, тест-менеджмента и QA-консалтинга. Эксперт ISTQB, TPI, TMMI.
Является актуальной уже много лет, этому вопросу посвящено немало исследований. В данной статье мы на примере реального проекта рассмотрим процесс внедрения KPI и методику оценки качества нашей работы.
Что такое KPI?
Итак, для начала обратимся к самому понятию KPI. KPI (Key Performance Indicator) – это показатель достижения успеха в определенной деятельности или в достижении определенных целей. Можно сказать, что KPI – это количественно измеримый индикатор фактически достигнутых результатов.
В нашем случае KPI на проекте – это показатель эффективности работы всей команды тестирования. Помимо термина KPI в статье будет использоваться термин «метрики», под которым мы будем понимать числовое значение для измерения этой эффективности.
Зачем нам KPI?
Теперь давайте поговорим о том, зачем нам понадобились KPI на проекте, и почему мы решили их внедрить. Здесь все просто: мы хотели видеть состояние проекта в любой момент времени и принимать превентивные меры, дабы избежать проблем. Благодаря KPI руководитель направления тестирования на проекте не только видит сильные и слабые стороны проекта и всей своей команды, но и может отслеживать в динамике последствия своих собственных управленческих решений (что было сделано правильно, какие из принятых решений были удачными или неудачными), а в дальнейшем – корректировать их.
Кроме того, в KPI можно включить не только общепринятые количественные показатели, но и качественные (например, «уровень удовлетворенности заказчика»). Но давайте обо всем по порядку!
Откуда взять KPI?
Каждый проект – вещь во многом уникальная. Не стоит полагать, что метрики с одного проекта хорошо «приживутся» на другом; их стоит разрабатывать с учетом специфики проекта и ожиданий/опасений вашего заказчика. А вот для превращения ожиданий в метрики потребуются время и терпение.

Как было у нас
Теперь я, как и обещала, расскажу о наших действиях на проекте.
Итак, моя команда тестировала внутреннее программное обеспечение заказчика, состоящее из нескольких больших функциональных блоков, а также интеграцию ПО с бэк-офисными системами хранения данных.
Сразу уточню, что под заказчиком в статье я буду понимать любое лицо, заинтересованное в тестировании продукта и стремящееся добиться того, чтобы продукт удовлетворил нужды конечных пользователей и отправился в промышленную эксплуатацию.
Заказчик пришел к нам с какими-то определенными ожиданиями от тестирования, со своей целью. На данном этапе моей задачей как руководителя направления тестирования на проекте стало выявление этих самых целей и ожиданий. Существует множество вариантов такого анализа – это опросы, заполнение брифов, устное общение. Самое важное – узнать, чего хочет заказчик, за что переживает, и что у него «болит».
Приведем примеры формулировок заказчика: «Из одного модуля программы в другой не «прилетают» сущности, а они там нужны, на них многое завязано»; «Не можем из старой программы в новую версию передать информацию»; «Мы полностью планируем переезд из одной системы в другую, поэтому будем настраивать передачу».

Сформировав ожидания (или опасения) нашего заказчика, мы должны трансформировать их в цель. Нетрудно догадаться, что целью нашего тестирования стало проведение комплексной оценки качества продукта путем интеграционного и функционального тестирования программного обеспечения заказчика.
Теперь нам предстояло провести процесс декомпозиции, то есть разбиения глобальной цели на небольшие решаемые задачи для проектной команды. Кстати, в этом мне помогла сама команда! Давайте посмотрим, как же это происходило, но для начала вновь уточним сам термин «декомпозиция», разложив все по полочкам.
Декомпозиция
 Что такое декомпозиция? Декомпозиция – это научный метод, использующий структуру задачи и позволяющий заменить решение одной большой задачи решением серии меньших подзадач, пусть и взаимосвязанных, но более простых. Принцип декомпозиции состоит в том, что тестируемое приложение (отдельный его модуль или функционал) можно рассматривать как состоящий из относительно независимых друг от друга подсистем, каждую из которых тестировать гораздо проще и понятнее, чем всю систему сразу.
Что такое декомпозиция? Декомпозиция – это научный метод, использующий структуру задачи и позволяющий заменить решение одной большой задачи решением серии меньших подзадач, пусть и взаимосвязанных, но более простых. Принцип декомпозиции состоит в том, что тестируемое приложение (отдельный его модуль или функционал) можно рассматривать как состоящий из относительно независимых друг от друга подсистем, каждую из которых тестировать гораздо проще и понятнее, чем всю систему сразу.
Если заказчик хочет получить тестирование интеграции – значит, нам нужно провести декомпозицию интеграционного функционального тестирования продукта. Для этого необходимо понять, из каких частей состоят системы заказчика, сколько вообще систем участвует в обмене данных, какие действия и над какими объектами могут совершать пользователи систем и т.д.
В теории все достаточно просто и ясно: из большой задачи нужно получить ряд маленьких. Казалось бы, ничего сложного, но на практике мы часто сталкиваемся с тем, что просто не понимаем критериев декомпозиции задачи, а потому делаем все наугад. Следствиями такого непонимания становятся неравномерная нагрузка на тестировщиков проекта, неверная оценка трудозатрат, неправильное понимание задач и разное представление о результатах. Для лучшего уяснения данной темы обратимся к принципу SMART.
Принцип SMART
Вообще, SMART – это мнемоническая аббревиатура, которую используют управленцы разных уровней для запоминания принципов постановки задач. Каждая буква аббревиатуры имеет свою расшифровку:
- S pecific – конкретный. Ставя задачу, мы должны четко понимать, какого результата хотим достичь. Результат должен быть однозначным и понятным всем участникам процесса – сотрудникам команды тестирования, заказчикам, руководителям разных уровней.
- M easurable – измеримый. Нам нужны задачи, которые могут быть измерены. Иными словами, измеримость предполагает наличие критериев – измерителей, показателей выполнения.
- A ttainable – достижимый. В данном случае определение «достижимый» я бы переименовала в «доступный» (доступный для выполнения сотрудником с определенным уровнем подготовки и квалификации). Грамотный руководитель никогда не даст новичку сверхсложную задачу, так как понимает, что новичок с ней просто не справится, а время, затраченное на попытки решения, уже не вернуть. Учет личностных особенностей и качеств сотрудников команды тестирования на проекте позволит очень четко (а главное – равномерно и посильно) распределить нагрузку, дать новичкам несложные задачи, а «звездочкам» и профи – задачи со сложной логикой в соответствии с их силами и навыками.
- R elevant – актуальный, значимый. Действительно ли выполнение задачи так важно для нас? Является ли данная задача необходимой именно сейчас? Что мы получим, если решим эту задачу? А если не решим?
- T ime-bound – ограниченный во времени. Любая задача должна иметь свой срок, в течение которого ее необходимо решить. Установление временных рамок и границ для выполнения задачи позволяет сделать процесс контролируемым и прозрачным. Руководитель в любой момент времени может увидеть прогресс выполнения задачи.
Итак, теперь у читателя есть понимание, по каким критериям можно декомпозировать большую задачу. Мы можем двигаться дальше.
После того, как большая задача разделена на ряд маленьких, нужно провести анализ каждой подзадачи. Давайте их выделим. Итак, в нашем проекте вырисовывался следующий набор действий:
- покрываем тестами весь основной функционал, задействованный в интеграции;
- разрабатываем тестовые сущности и данные;
- тестируем задачи по доработке функционала;
- заводим дефекты, найденные при тестировании;
- проверяем релизы и хот-фиксы;
- убеждаемся, что на каждой новой версии продукта из одной системы в другую возможно передать два приоритетных продукта.

Помимо этих основных подзадач я выделила еще несколько дополнительных:
- мы не хотим тратить время, объясняя разработчикам, «в чем тут баг, и как его можно воспроизвести», а поэтому будем заводить грамотные и понятные дефекты;
- наши работы по тестированию должны быть максимально прозрачными, поэтому мы будем предоставлять промежуточный статус по состоянию версии заказчику;
- мы хотим, чтобы заказчику понравилось с нами работать, и в следующий раз он снова обратился к нам.
- каково состояние версии;
- какие модули продукта являются самыми критичными и забагованными;
- на какие модули следует обратить особое внимание;
- какие показатели работают для приоритетных продуктов;
- можно ли отдавать продукт в промышленную эксплуатацию.
Теперь давайте вместе пройдемся по каждой подзадаче и рассмотрим измеримые показатели (метрики).
Метрики, из которых складываются KPI
Покрытие функционала тестами. Как мы его можем измерить? Мы остановились на метрике «% покрытия xx числа модулей продукта тестами» (более подробную информацию о том, как это посчитать, вы можете найти в статье Натальи Руколь ).
По клику на картинку откроется полная версия.
Разработка тест-кейсов и тестовых сущностей. Здесь мы решили работать с метрикой «количество модулей / функциональных блоков продукта, для которых разработано 100% сущностей».
Тестирование доработок заказчика. В данном случае мы просто посчитали число протестированных доработок на версии и среднее время, затраченное командой на проверку. Мы собрали эти показатели для того, чтобы оценить, на что была направлена версия (на багфиксинг или на внедрение новых функциональностей заказчика), а следовательно, укладываемся ли мы по срокам реализации определенных фич.
«Заведение дефектов». Мы решили воспользоваться несколькими метриками, которые бы давали нам информацию о состоянии версии: «количество дефектов, заведенных командой», «количество дефектов приоритета Blocker на версии».
«Тестировать релизы и хот-фиксы»
мы решили метриками «% протестированных задач, входящих в релиз и/или хот-фикс» (отношение проверенных задач к общему числу задач версии), «% тест-кейсов, пройденных на версии» и «% успешности прохождения кейсов на версии».
Последнюю метрику мы считаем по формуле:

где P1 – passed-шаги по первому блоку,
P2 – passed-шаги по второму блоку,
Pn – passed-шаги по n-ному блоку,
A1 – число шагов по первому блоку,
А2 – число шагов по второму блоку,
An – число шагов n-ного блока,
N – общее число всех блоков продукта.
Для измерения задачи, связанной с работоспособностью приоритетных продуктов, мы специально разработали матрицу (в ней отмечалось, работает или не работает то или иное значение для продукта) а далее подсчитали «% значений, работающих для продукта 1 и продукта 2 на версии». Считаем по формуле:

где Pп1 – это число работающих значений для продукта один,
Aп1 – все значения для продукта один.
По клику на картинку откроется полная версия.
Разобравшись с основными задачами, мы перешли к дополнительным.
Напомню, что мы не хотели тратить дорогое нам время на объяснения багов и комментирование отчетов, но в то же время нам было важно, чтобы заказчик был доволен нашей работой. Таким образом для первой подзадачи, мы решили использовать количественные показатели «% отклоненных дефектов на версии с резолюцией Can’t reproduce», а для второй – «количество обращений заказчика с просьбой прокомментировать промежуточный отчет» и качественный показатель «удовлетворенность заказчика нашей работой».
Для оценки «удовлетворенности заказчика» мы ввели три уровня – «все отлично», «есть небольшие замечания / вопросы к работе» и «все плохо, заказчик недоволен». Этот показатель, кстати, вообще очень помогает с оперативным принятием решений внутри проектной команды. Если заказчик чем-то недоволен или огорчен, мы по «горячим следам» проводим обсуждение: стараемся минимизировать риски, понять причины недовольства, в максимально короткие сроки проработать решение и представить его заказчику.
По клику на картинку откроется полная версия.
Что в итоге нам дают KPI
Подготовка KPI проекта – процедура затратная, но интересная и полезная, и вот почему.
Собирая перечисленные выше метрики, я могу получить ответы на вопросы: что именно моя команда сделала хорошо, по каким показателям мы выросли, были ли правильны и своевременны мои управленческие решения. В любой момент времени я могу ответить заказчику на следующие вопросы:
После внедрения метрик на моем проекте стало легче готовить промежуточную отчетность для заказчика, вся проектная команда (а у ребят есть доступ к KPI проекта) прикладывала максимум усилий для роста наших по
казателей, все стали более внимательными и сосредоточенными!
Вместо заключения

В «Лаборатории качества» мы пошли чуть дальше и все же решили собирать базу метрик, которые применимы на наших проектах. Нет, я не говорю, что можно брать готовый материал и работать с ним, но каждый менеджер, столкнувшийся с темой внедрения KPI на своем проекте, может обратиться к этой базе, посмотреть метрики, из которых собираются KPI на других проектах, и адаптировать эти метрики под свои нужды. Также мы подготовили внутренний регламент (своеобразную инструкцию по внедрению KPI на проектах), с помощью которого этот процесс проходит плавно и безболезненно.
Не бойтесь потратить время на подготовку и внедрение KPI на проекте: эти затраты полностью окупятся! Ваш заказчик будет удовлетворен проведенными работами и отличным качеством продукта. Он вновь и вновь обратится к вам за помощью!